

In the ever-evolving world of Natural Language Processing (NLP), ModernBERT vs BERT has become a key topic of discussion. A new contender, ModernBERT, has emerged to rival the widely acclaimed BERT model. Designed to address the limitations of its predecessor, ModernBERT delivers significant improvements in speed, accuracy, and efficiency. Therefore, this article explores the key differences between ModernBERT and BERT, highlighting ModernBERT’s advancements in text embeddings and NLP tasks.
Revisiting BERT: A Game-Changer in NLP
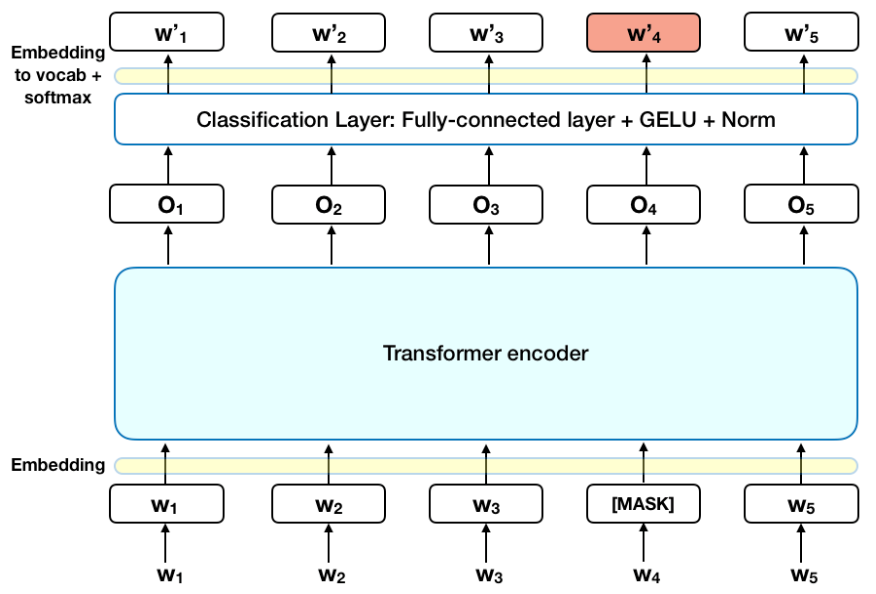
BERT Explained: As a state-of-the-art language model for NLP
Introduced in 2018 by Google researchers Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova, BERT (Bidirectional Encoder Representations from Transformers) revolutionized NLP by employing bidirectional context learning. Having been trained on 3.3 billion words across 104 languages, BERT’s ability to understand context from both directions (left-to-right and right-to-left) therefore made it a foundational model in NLP.
Consequently, with over 68 million downloads on HuggingFace Hub, BERT remains a top choice in NLP, trailing only the all-MiniLM-L6-v2 model. However, six years later, ModernBERT has arrived to push the boundaries further.
Introducing ModernBERT: A Next-Gen NLP Model
Pareto Efficiency: Runtime vs Glue

Pareto Efficiency: Runtime vs Glue
Moreover, on December 19, 2024, a team of researchers—Benjamin Warner, Antoine Chaffin, Benjamin Clavié, and others—unveiled ModernBERT. This model series is Pareto-optimized for speed and accuracy, trained on an impressive 2 trillion unique tokens from diverse English-language sources, including web documents, code, and scientific papers.
Comparing ModernBERT and BERT
1. Context Length
- BERT: Limited to 512 tokens.
- ModernBERT: Supports up to 8,192 tokens, making it ideal for processing lengthy and complex texts.
Why it matters: This is important because longer context lengths significantly enhance performance in tasks such as summarization, question-answering, and structured data processing.
2. Architectural Enhancements
ModernBERT introduces cutting-edge innovations:
- Rotary Positional Embeddings (ROPE): Improves token position understanding.
- GeGLU Layers: Enhances activation functions and training stability.
- Flash Attention: Combines local/global attention mechanisms for optimized speed and resource usage.
- Sequence Packing: Reduces computational waste by eliminating padding tokens.
3. Training Data
- BERT: Trained on datasets like Wikipedia and Google Books.
- ModernBERT: Utilizes a more diverse dataset, including programming languages, enabling superior performance in code-related tasks.
4. Performance Metrics

- BERT: Historically, BERT was a benchmark leader; however, it has now been outpaced by newer models.
- ModernBERT: Outperforms BERT, RoBERTa, and ELECTRA on benchmarks like GLUE, achieving top-tier results.
5. Speed and Efficiency

ModernBERT vs BERT – Efficiency
- BERT: Requires extensive computational resources.
- ModernBERT: On the other hand, ModernBERT is up to 400% faster in training and inference, with better performance on standard GPUs. In fact, it is twice as fast as DeBERTa and up to 4x faster in cases with mixed-length inputs.
6. Memory Usage
- BERT: High memory consumption.
- ModernBERT: Uses 80% less memory than DeBERTaV3 while maintaining similar performance.
7. Variants
- ModernBERT:
- ModernBERT-Base: 22 layers, ~139M parameters.
- ModernBERT-Large: 28 layers, ~395M parameters.
- BERT:
- BERT-Base: 12 layers, 110M parameters.
- BERT-Large: 24 layers, 340M parameters.
8. Hardware Compatibility
Notably, ModernBERT is optimized for consumer-level GPUs, making it more accessible for real-world applications compared to BERT.
How to Use ModernBERT
If you’re currently using BERT, switching to ModernBERT is seamless. Simply replace the model without requiring code modifications to benefit from its advanced features.
Conclusion: ModernBERT’s Advantages in NLP
Ultimately, whether you’re summarizing text, answering questions, or processing code, ModernBERT offers a flexible and efficient solution. In this way, it marks a significant leap forward in NLP capabilities.
So, take your NLP projects to the next level—try ModernBERT today!
ModernBERT vs BERT Kaggle Notebook(Coming Soon… !) Stay tuned for upcoming notebooks comparing ModernBERT and BERT in real-world applications.
💡💡💡 With ModernBERT pushing the boundaries of what we thought was possible, could it soon replace BERT in every NLP task? What untapped potential lies in these advancements, and how will they reshape the future of AI? Indeed, the journey is just beginning.
Experience In-Depth, Real-Time Analysis
For just $200/year (not $200/hour). Stop wasting time with alternatives:
- Consultancies take weeks and cost thousands.
- ChatGPT and Perplexity lack depth.
- Googling wastes hours with scattered results.
Enki delivers fresh, evidence-based insights covering your market, your customers, and your competitors.
Trusted by Fortune 500 teams. Market-specific intelligence.
Explore Your Market →One-week free trial. Cancel anytime.
Related Articles
If you found this article helpful, you might also enjoy these related articles that dive deeper into similar topics and provide further insights.
- E-Methanol Market Analysis: Growth, Confidence, and Market Reality(2023-2025)
- Battery Storage Market Analysis: Growth, Confidence, and Market Reality(2023-2025)
- Carbon Engineering & DAC Market Trends 2025: Analysis
- Climeworks 2025: DAC Market Analysis & Future Outlook
- Climeworks- From Breakout Growth to Operational Crossroads
Huseyin Cenik
He has over 10 years of experience in mathematics, statistics, and data analysis. His journey began with a passion for solving complex problems and has led him to master skills in data extraction, transformation, and visualization. He is proficient in Python, utilizing libraries such as NumPy, Pandas, SciPy, Seaborn, and Matplotlib to manipulate and visualize data. He also has extensive experience with SQL, PowerBI and Tableau, enabling him to work with databases and create interactive visualizations. His strong analytical mindset, attention to detail, and effective communication skills allow him to provide actionable insights and drive data-driven decision-making. With a deep passion for uncovering valuable patterns in data, he is dedicated to helping businesses and teams make informed decisions through thorough analysis and innovative solutions.