

The rapid growth of Large Language Models (LLMs) has created new ways to add external knowledge to text generation. Among these, Cache vs. Retrieval Augmented Generation (CAG or RAG) stand out, each offering different benefits and challenges. While RAG has been the go-to method for using dynamic external data, recent studies, like those by Chan et al. (2024), show that CAG is a faster and simpler option for stable knowledge tasks. 🚀
This article will explore the differences between Cache vs. Retrieval Augmented Generation (CAG or RAG), helping you choose the best method for your needs. 🎯

Cache vs. Retrieval Augmented Generation (CAG or RAG)
1. What is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) improves the output of a language model by getting relevant information in real-time. 📥
Process Steps:
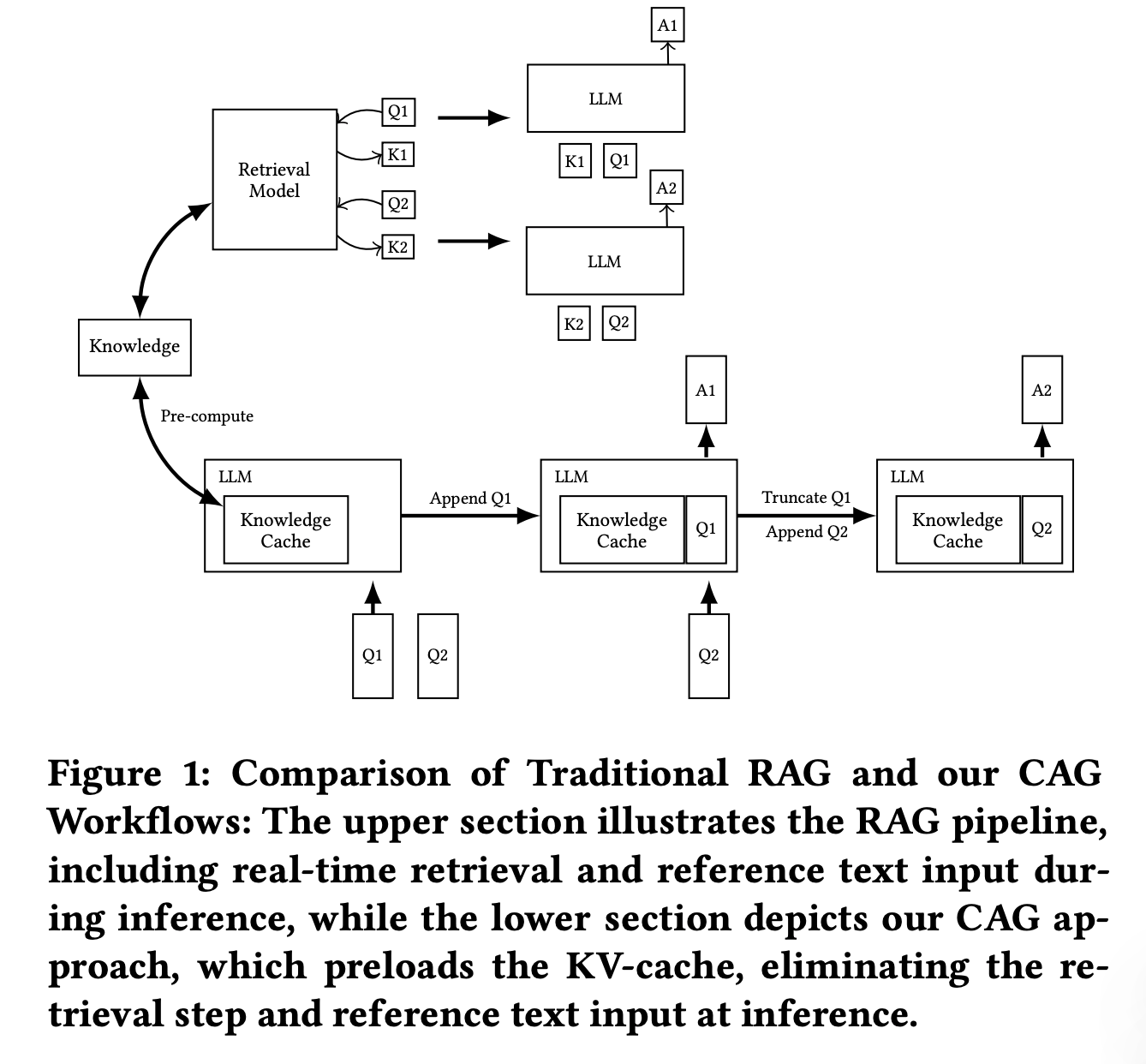
1️⃣ Retrieval: The system retrieves top-ranking documents or text segments (e.g., from a vector database or BM25-based indices).
2️⃣ Augmentation: The system appends the retrieved segments to the user’s query.
3️⃣ Generation: The LLM generates the final output by processing the augmented prompt. 📝
Advantages of RAG
📅 Up-to-date Information: RAG stays current by fetching real-time data.
⚖️Smaller LLMs: By storing knowledge externally, the model can be made lighter.
🔍Reality Check: RAG reduces hallucinations (false information) by referencing real documents.
Challenges of RAG
⏳ Latency: Each query includes an extra retrieval step, which may slow down response time.
⚠️ Incorrect Data: If irrelevant or outdated documents are retrieved, it may lead to mistakes.
⚙️ System Complexity: Managing an external index or database can be difficult, especially with frequent updates.
2. What is Cache-Augmented Generation (CAG)?
CAG or RAG – Cache vs. Retrieval Augmented Generation – Comparison Cag with Rag
CAG, instead of relying on retrieval, preloads all the necessary context into the model and stores calculated results in advance. 🚀
How It Works:
1️⃣ Preloading Information: The system feeds relevant documents or domain knowledge into the model ahead of time.
2️⃣ KV-Cache (Key-Value Cache): Modern LLMs store intermediate states (KV cache). CAG precomputes these for a given knowledge set so they can be quickly reused.
3️⃣ Faster Output Generation: When a query comes in, the model uses the preloaded cache without the need for retrieval. 🚀
Advantages of CAG
🚀Low Latency: The system skips the retrieval step for fast responses.
🧩Simplicity: No need for complicated RAG pipelines with external retrieval and augmentation components.
🔗Integrated Context: Since the model processes everything from the start, it can improve multi-step reasoning.
Potential Issues with CAG
⚖️ Context Size Limitations: If your knowledge set is too large, you can’t load it all into the model.
⏱️ Initial Computation: The system requires more processing upfront to precompute the KV cache.
📰 Stale Data: If your data changes frequently (e.g., news), you may need to reload the cache regularly.
3. Retrieval-Augmented Generation vs. Cache-Augmented Generation (Rag or Cag): Which One Performs Better?
In the study by Chan et al. (2024), both methods were compared across tasks like HotPotQA (multi-step reasoning) and SQuAD (single-turn comprehension). 🔍
RAG Setup:
📡 Dense and sparse retrieval methods fetch top documents, which the system then combines with the query to process by the model.
CAG Setup:
📂 The system preloads information into the KV cache, and when a query arrives, it processes it directly with that cache.
Key Performance Insights:
💯 Accuracy: CAG can outperform RAG, especially when the entire corpus fits within the context window. Furthermore, CAG provides consistent results for stable knowledge tasks.
⚡ Latency & Complexity: On the other hand, RAG often incurs additional latency due to the retrieval step. In contrast, CAG skips this retrieval process, making it faster and more efficient.
4. When to Use RAG vs. CAG?
Ideal Scenarios for RAG:
⚡ Rapidly Changing Information: For example, such as real-time stock prices or breaking news.
🌍 Massive Datasets: When your data is too large to fit into the model, RAG is necessary.
🔍 Citation Requirements: If you need to reference where the data came from, RAG dynamically fetches the most relevant sources.
Ideal Scenarios for CAG:
📚 Small, Stable Knowledge Sets: If your knowledge base is small enough to fit into the model and doesn’t change often, CAG is ideal.
⚡ Low Latency, High Consistency: For real-time chat systems or queries that often access the same data, CAG excels.
🧠 Reduced System Complexity: On the other hand, CAG simplifies the process by eliminating the need for external database management or indexing.
5. Can RAG and CAG Be Combined?
Absolutely, in fact! 🤝
A combined method offers the the advantages of both: use CAG for frequently accessed documents and RAG for rare or new information. 🏗️
✔️ Flexibility: This approach lets you maintain speed and simplicity with CAG, while RAG handles the dynamic aspects.
✔️ Efficiency: By combining both methods, you avoid the complexity of a full RAG pipeline, ensuring streamlined performance.
6. Conclusion: Which Is Better?
There is certainly no single answer! 🧐
Cache-Augmented Generation vs. Retrieval-Augmented Generation (Cag or Rag)
📊Retrieval-Augmented Generation: Best suited for large, changing, and often updated datasets.
💡Cache-Augmented Generation: Ideal for small, stable knowledge bases where speed and simplicity take precedence.
🔮Key Insight: As context window sizes expand and LLMs gain long-term memory capabilities, CAG will likely become an increasingly attractive choice! 🎉
Cache-Augmented Generation (CAG) accelerates the integration of external knowledge, making it a faster and simpler option, especially for stable or medium-sized knowledge sets. However, Retrieval-Augmented Generation (RAG) still plays a crucial role in handling massive, dynamic contexts. 🚀
Thank you!
If you found this post useful, feel free to leave a comment or share it with AI enthusiasts. Try out RAG, CAG, or both, and let us know which approach works best for you! 💬🔗
Related Articles
If you found this article helpful, you might also enjoy these related articles that dive deeper into similar topics and provide further insights.
- E-Methanol Market Analysis: Growth, Confidence, and Market Reality(2023-2025)
- Carbon Engineering & DAC Market Trends 2025: Analysis
- Climeworks 2025: DAC Market Analysis & Future Outlook
- Battery Storage Market Analysis: Growth, Confidence, and Market Reality(2023-2025)
- Hydrogen Bus Market 2026: Tech Readiness & Deployments
Huseyin Cenik
He has over 10 years of experience in mathematics, statistics, and data analysis. His journey began with a passion for solving complex problems and has led him to master skills in data extraction, transformation, and visualization. He is proficient in Python, utilizing libraries such as NumPy, Pandas, SciPy, Seaborn, and Matplotlib to manipulate and visualize data. He also has extensive experience with SQL, PowerBI and Tableau, enabling him to work with databases and create interactive visualizations. His strong analytical mindset, attention to detail, and effective communication skills allow him to provide actionable insights and drive data-driven decision-making. With a deep passion for uncovering valuable patterns in data, he is dedicated to helping businesses and teams make informed decisions through thorough analysis and innovative solutions.